
Configuration drift is the silent killer of remote access reliability. It doesn’t crash your connection at 9 AM on Monday. It quietly shifts a registry value, lets a certificate creep toward expiration, or allows a Group Policy override to accumulate over weeks — and then, one morning, 200 hybrid work employees can’t reach their corporate resources, and nobody knows why.
The traditional engineering response is to write rules. If certificate expiry is less than 5 days, alert. If the DNS server doesn’t match the expected value, flag it. If the firewall profile changed, report. These rules work — until they don’t. And they stop working precisely when you need them most: when the drift is subtle, when it spans multiple configuration dimensions simultaneously, and when you’re supporting a fleet that runs a dozen different remote access client stacks with completely different configuration schemas.
This is why we chose contrastive learning with Siamese neural networks as the core drift detection mechanism in ReXGuardianCA, and this post walks through the technical reasoning, the architecture, and the engineering tradeoffs.
The Problem with Rules at Scale
Rule-based configuration diffing follows a straightforward pattern: define a golden baseline, compare the current state against it, and flag any delta. For a single remote access client on a single endpoint, this works fine. The problem emerges at fleet scale across heterogeneous environments.
First, the baseline itself drifts intentionally. IT pushes a new cipher suite policy. A security team rotates gateway certificates. A new client version ships with different default settings. Every intentional change requires updating the baseline rules — and if you miss one, you generate false positives that train your operations team to ignore alerts.
Second, configuration schemas differ across client stacks. The configuration surface for one enterprise remote access client (XML profiles, registry keys, authentication parameters) bears little resemblance to another (JSON policy files, different registry paths, different certificate stores). Maintaining per-client rule sets means N separate rule codebases, each with its own maintenance burden and failure modes.
Third, rules can’t express combinatorial interactions. A single setting change might be benign. But that same change combined with a specific driver version and a particular network adapter state might reliably predict a connection failure in 48 hours. Encoding these multi-dimensional interactions as hand-written rules is combinatorially intractable.
We needed a detection mechanism that learns what “normal drift” looks like for a given endpoint in its specific context, generalizes across client stacks without per-client rule maintenance, and flags deviations that correlate with actual connectivity failures — not just deviations from a static template.
Why Siamese Networks
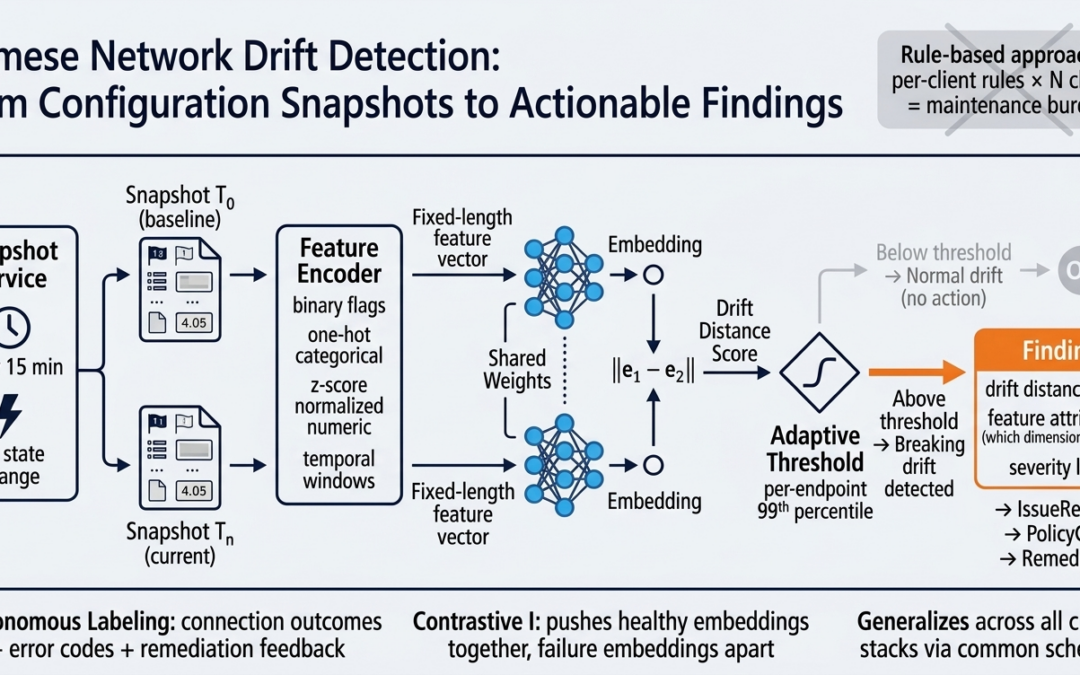
A Siamese neural network is a comparator architecture. It takes two inputs — in our case, two configuration state vectors captured at different points in time — processes each through identical weight-sharing encoder branches, and outputs an embedding distance that represents how “different” the two states are in a learned metric space.
The key insight is what the network learns to measure. Unlike a naive diff that treats every changed field equally, a Siamese network trained with contrastive learning discovers which configuration changes matter and which don’t. It learns, from labeled or pseudo-labeled examples, that a change to the authentication method field has high significance while a change to the UI language preference has near-zero significance — even though both show up as “changed” in a raw diff.
This is precisely the property we needed: a drift detector that is semantically aware, not just syntactically aware.
The Snapshot Service: Capturing Configuration State
The upstream data source for drift detection is the Snapshot Service, a background component that continuously captures vendor-agnostic configuration state from whatever remote access client is active on the endpoint.
For each supported client stack, the Snapshot Service reads the relevant configuration surfaces: profile definitions, registry keys, certificate metadata (issuer, expiry, thumbprint), Group Policy state, firewall rules, DNS resolver configuration, routing table entries, and authentication parameters. These are normalized into a common schema — a flat feature vector where each dimension represents a specific configuration attribute, regardless of which client stack it originated from.
Snapshots are captured on two triggers: periodically (every 15 minutes by default) and on any connection state change event. This dual-trigger strategy ensures we have both steady-state longitudinal data for trend analysis and high-resolution data around the moments that matter most — when connections succeed or fail.
All snapshots are stored in the local time-series database with DPAPI-NG encryption. No configuration data ever leaves the device.
The Feature Encoder: From Raw Config to Structured Tensors
Raw configuration snapshots are heterogeneous: some fields are boolean (firewall enabled/disabled), some are categorical (authentication method: certificate, EAP-TLS, PEAP), some are numeric (days until certificate expiry), and some are text (error message strings from event logs).
The Feature Encoder transforms this mixed-type data into structured tensors suitable for neural network consumption:
Binary flags are passed through directly: certificate expiring within threshold, DNS server matches expected, intranet route present, required services running.
Categorical fields are one-hot encoded or hash-embedded, depending on cardinality. Low-cardinality fields like authentication method get one-hot encoding. High-cardinality fields like error message categories get learned hash embeddings that map to dense vectors.
Numeric fields are z-score normalized relative to the endpoint’s own historical distribution. This is important — what counts as “normal” latency or “normal” reconnect frequency varies dramatically across endpoints depending on the user’s ISP, geographic location, and typical usage patterns. Per-endpoint normalization prevents a user on a high-latency satellite connection from being flagged as anomalous simply because their baseline differs from the fleet average.
Temporal features are derived from the time-series: rate of change in key metrics over rolling windows (7-day, 30-day), variance in connection stability, and trend direction for certificate expiry countdown.
The output is a fixed-length feature vector that represents the complete configuration and health state of the endpoint at a given moment, in a form that the Siamese network can consume.
Contrastive Loss and the Training Strategy
The Siamese network is trained using contrastive loss on pairs of configuration snapshots. The training signal comes from a combination of explicit labels and autonomous pseudo-labels:
Positive pairs (similar, should have low distance): Two snapshots from the same endpoint captured during a period of stable connectivity. These represent “normal drift” — the kind of configuration evolution that doesn’t predict failure.
Negative pairs (dissimilar, should have high distance): A snapshot captured before a connectivity failure paired with the last known-good snapshot. These represent “breaking drift” — configuration changes that preceded an actual outage.
The critical question is: where do the labels come from? On an endpoint, you don’t have a team of analysts manually labeling configuration snapshots. Our autonomous labeling strategy uses three heuristic signals:
Connection outcome scoring. If a remote access session is established and remains stable for more than a threshold duration, the preceding configuration snapshot is labeled “good.” If a connection attempt fails, or if a session drops within a short window, the preceding snapshot is labeled “problematic.” These outcome-derived labels are noisy but abundant.
Error code mapping. Windows event logs and client-specific logs contain error codes that map to known failure categories. An error indicating server unreachable paired with a specific configuration state provides a strong supervisory signal.
Self-training from successful reconnections. When the remediation pipeline fixes an issue, the pre-fix and post-fix configuration snapshots form a naturally labeled pair: the pre-fix state is “broken,” the post-fix state is “working.” This creates a continuous feedback loop where every successful remediation generates training data for the drift detector.
The contrastive loss function pushes the network to produce embeddings where snapshots from stable periods cluster together and snapshots preceding failures are pushed far away in embedding space. At inference time, the network compares the current snapshot against a running centroid of recent “healthy” embeddings. When the distance exceeds a learned threshold, drift is flagged.
Why This Generalizes Across Client Stacks
The most important engineering property of this approach is that we don’t need separate models for each remote access client stack. Because the Feature Encoder normalizes all client configurations into a common schema, the Siamese network operates on an abstracted representation that is vendor-agnostic.
When we add support for a new client stack, the work is in the Snapshot Service (teaching it to read the new client’s configuration surfaces) and the Feature Encoder (mapping new fields to the common schema). The Siamese network itself requires no retraining — it already knows how to measure drift in the abstract feature space. Over time, as the endpoint accumulates connection outcome data for the new client, the model’s predictions for that stack naturally improve through the federated learning loop.
This is a fundamental advantage over rule-based approaches, where adding a new client stack means writing and maintaining an entirely new rule set. With contrastive learning, the marginal cost of supporting an additional client is a configuration mapping, not a model rewrite.
Calibration: Minimizing False Positives
A drift detector that cries wolf is worse than no detector at all — it trains operations teams to ignore alerts and undermines trust in the autonomous remediation pipeline downstream. Calibration is therefore critical.
We use per-endpoint adaptive thresholds rather than fleet-wide static thresholds. Each endpoint maintains a running distribution of embedding distances from its healthy centroid. The alert threshold is set at a configurable percentile of that distribution (default: 99th percentile). This means an endpoint that experiences more routine configuration churn (perhaps because IT frequently pushes policy updates to that machine) naturally has a higher threshold than a stable endpoint that rarely changes.
The threshold also adapts over time. If an endpoint’s configuration legitimately shifts — say, the organization migrates to a new authentication method — the healthy centroid gradually moves to reflect the new normal, and the threshold recalibrates.
Integration with the Remediation Pipeline
When the Siamese network flags drift, it produces a Finding — the same immutable data structure used by deterministic analyzers. The Finding includes the drift distance score, a breakdown of which feature dimensions contributed most to the distance (derived from gradient attribution on the encoder), and the severity level based on how far the distance exceeds the threshold.
This Finding flows into the IssueRegistry, through PolicyGate, and into the RemediationManager — exactly like any other detected issue. The drift detector doesn’t need special handling in the pipeline. It’s just another analyzer that happens to use a neural network instead of a hand-coded rule.
The feature attribution is particularly valuable for the downstream Phi Silica explanation engine. When Phi Silica generates a human-readable diagnostic report, it can say “Configuration drift detected: the DNS resolver configuration changed from the expected value, and the client certificate will expire in 3 days” rather than a generic “anomaly detected.” This specificity is what makes the escalation reports useful to L2 engineers.
Dynamic Adaptation as the Software Environment Evolves
There’s a deeper advantage to ML-based drift detection that becomes apparent over time, and it’s one that rule-based approaches fundamentally cannot replicate.
Enterprise endpoints are not static environments. Remote access client software gets updated — sometimes by IT, sometimes by vendors pushing silent updates, sometimes by Windows Update pulling in a new driver. Security agents get upgraded. Operating system builds advance. Certificate authorities rotate. Each of these changes subtly alters the configuration surface that the Snapshot Service captures, and some combinations of version changes create connectivity problems that no individual change would cause on its own.
A rule-based system is blind to this combinatorial evolution. It can only flag conditions that someone has already identified, encoded, and deployed. When a new client version ships with a subtly different default behavior — or when a specific combination of client version, OS build, and network adapter driver creates an intermittent failure — rules don’t catch it until a human investigates, understands the interaction, writes a new rule, tests it, and pushes it to endpoints. That cycle takes days to weeks, and the affected employees are filing tickets the entire time.
The Siamese network handles this organically. It doesn’t need to know that a specific client version combined with a particular OS build and a particular network driver creates problems. It observes that endpoints running that combination are producing configuration snapshots that increasingly diverge from their own healthy centroids, and that the divergence correlates with connection failures. The model surfaces a drift Finding — and crucially, it does this without anyone ever having written a rule for that specific version combination.
This is where the federated learning loop (covered in a dedicated post) amplifies the effect. When one endpoint in the fleet encounters a problematic version combination and the drift detector flags it, that signal — in the form of anonymized gradient updates — propagates to the fleet-wide model through secure aggregation. Other endpoints running the same combination begin to benefit from that learned pattern before they experience failures themselves. The system effectively creates a fleet-wide early warning network for emerging software compatibility issues, with zero centralized telemetry and zero human rule authoring.
Over months and years of deployment, this dynamic adaptation means the ReXGuardian AI Agent’s detection accuracy improves continuously as the software environment evolves — in contrast to rule-based systems, which degrade over time as their static rules become increasingly stale relative to the moving target of real-world endpoint configurations.
What We Learned
Building a production drift detector taught us several lessons worth sharing:
Autonomous labeling quality matters more than quantity. Early in development, we used every connection outcome as a label. The resulting training set was dominated by “good” examples (most connections succeed), making the model conservative and slow to flag genuine drift. Filtering to only use strong signals — clear failures with known error codes, and confirmed fix events from the remediation pipeline — produced dramatically better separation in embedding space.
Per-endpoint normalization is non-negotiable. A fleet-wide model that treats all endpoints identically will either miss drift on high-churn endpoints or false-alarm constantly on stable ones. The per-endpoint healthy centroid and adaptive threshold solved this elegantly.
Gradient attribution for explainability is worth the compute cost. The initial implementation just reported a drift score. Ops teams couldn’t act on it. Adding per-feature attribution — “which configuration dimensions drove this score” — transformed the Finding from an opaque alert into an actionable diagnostic. The additional compute is negligible on modern hardware.
The model’s value compounds as the environment changes. We initially justified the ML approach on accuracy grounds — contrastive learning catches drift that rules miss. But in production, the more powerful argument turned out to be longevity. Rule-based systems require constant maintenance as the software landscape evolves. Our drift detector adapts automatically. Six months after deployment, it was catching version-interaction failures that didn’t exist when the model was first trained, because the federated learning loop had continuously incorporated new failure patterns from across the fleet. The maintenance cost of the ML approach actually decreases over time, while the maintenance cost of a rule-based approach only increases.
The result is a drift detection system that learns, adapts, generalizes across client stacks, and produces actionable Findings — all running entirely on-device, with zero cloud dependency.
Emmett O’Brien leads the engineering organization behind ReXLytics’ Hybrid Work ERP platform and the Edge-AI-powered ReXGuardian suite for enterprise connectivity and cybersecurity. Learn more at ReXLytics.com or connect with Emmett O’Brien on LinkedIn.