
A remote-access expert on every device—no tickets required.

Zero-wait help desk—on your laptop.

How it works
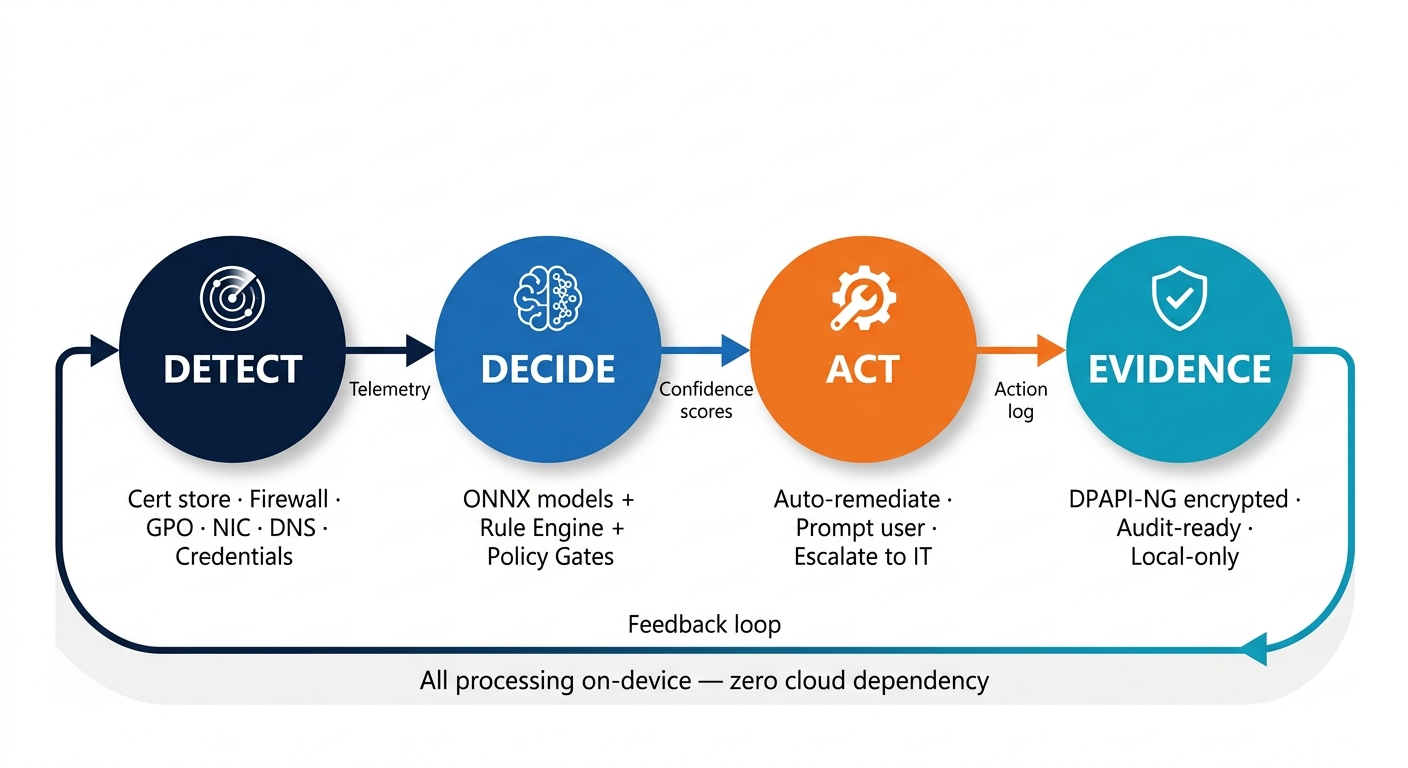
Purpose-built for remote connectivity resilience


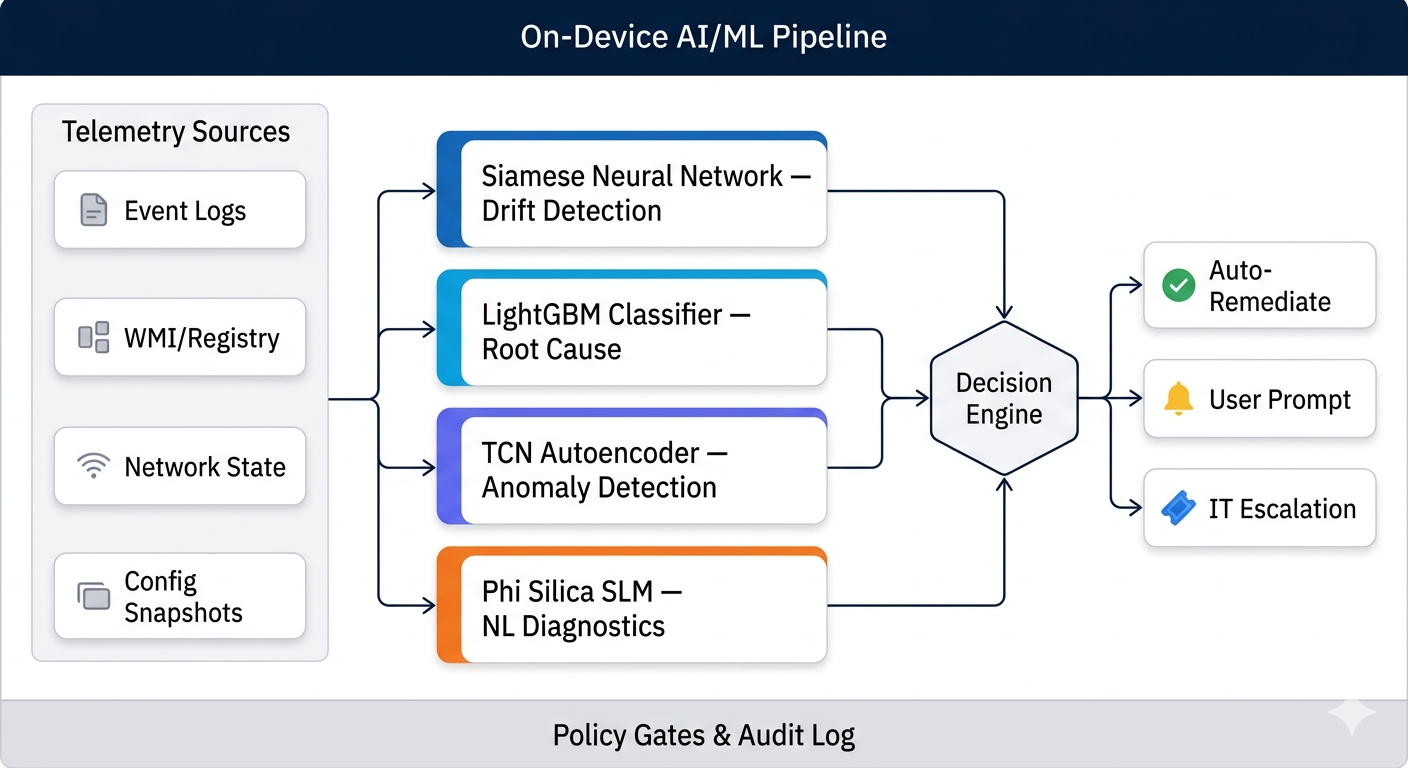
Multiple custom-trained ML model families. Fully on-device. Zero cloud dependency.
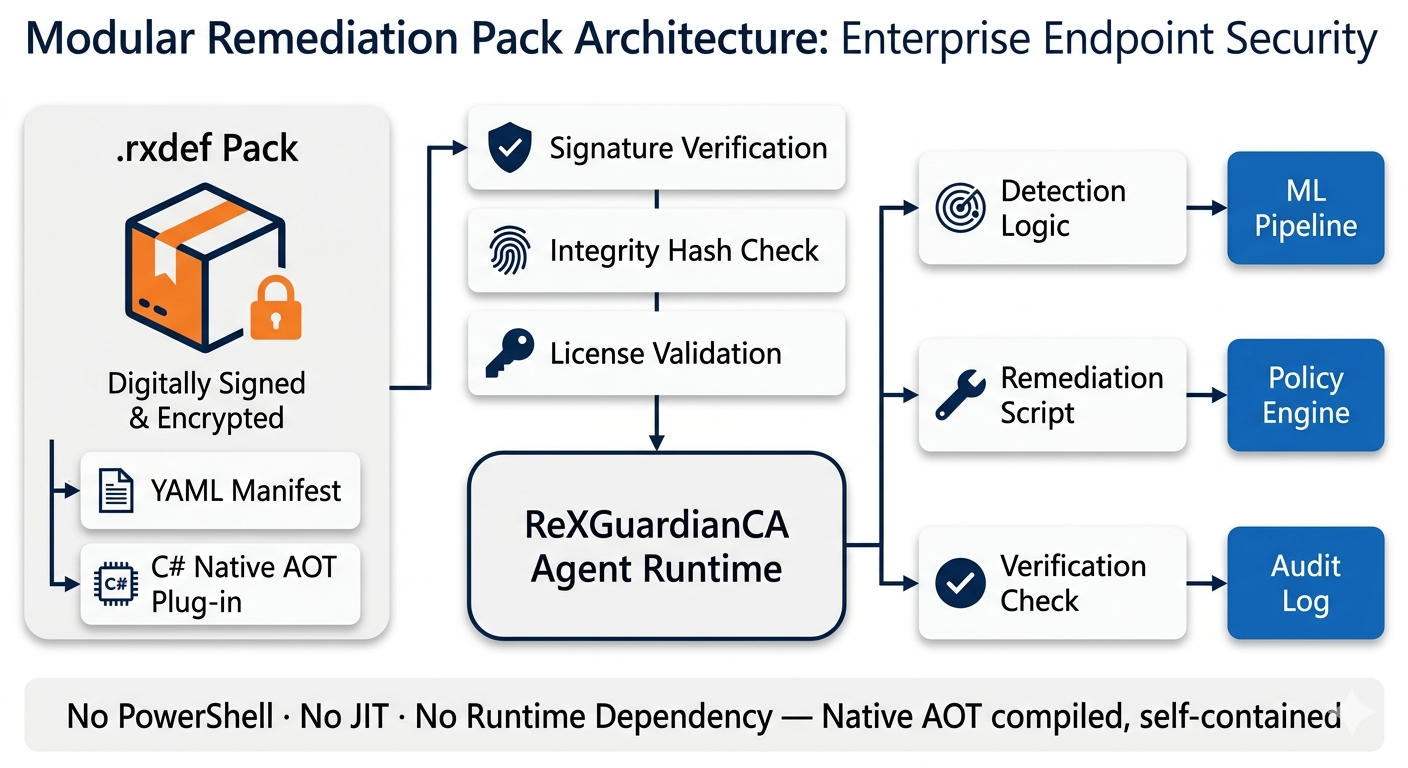
Remediation definition packs (.rxdef) combine ML findings with policy-driven fix scripts.
Supported Remote-Access Solution Plug-ins
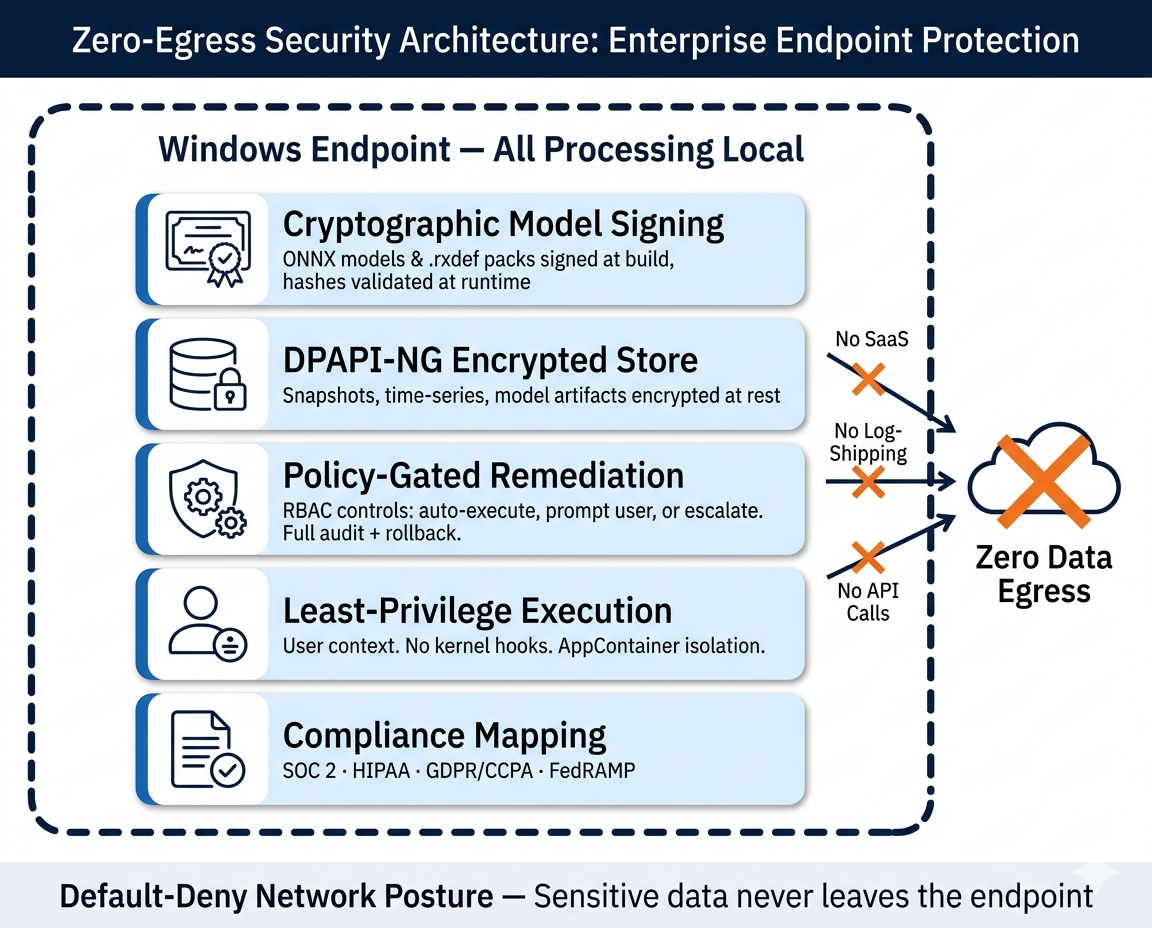
Fully local ML pipeline. Encrypted telemetry. Cryptographic model signing.
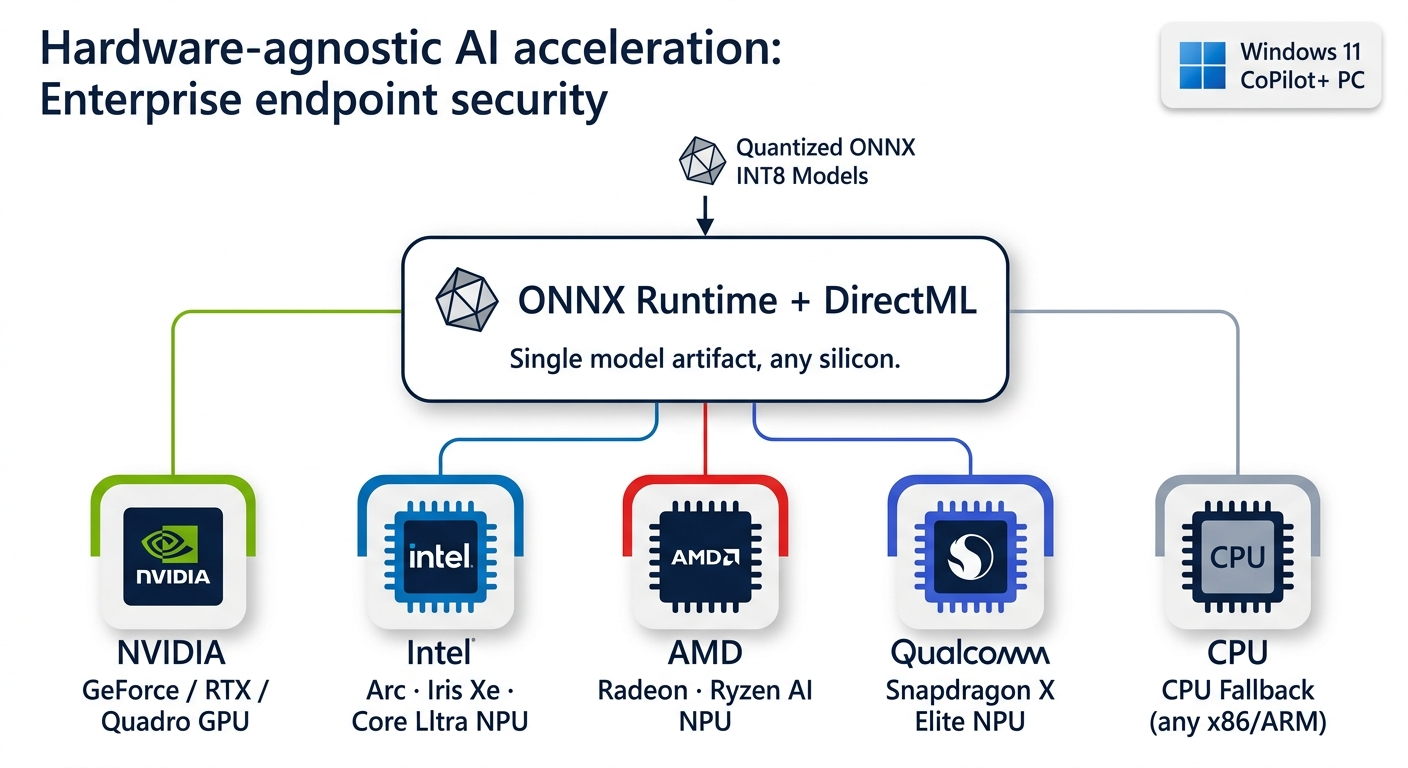
ONNX Runtime + DirectML: cross-silicon inference across every major NPU and GPU family.
FAQ
Does it ship data to the cloud?
No. All AI/ML inference runs locally on the endpoint via ONNX Runtime. Zero data egress by design. Policies control what’s stored locally and for how long—no log-shipping, no remote API calls, even when the VPN is down.
Will it conflict with our VPN/ZTNA client?
ReXGuardianCA is vendor-agnostic and uses only documented Windows/Microsoft APIs—no kernel hooks, no driver-level interception. Remediation actions are policy-gated; every fix executes through the same controlled interface with rollback and audit.
Can we trust automated fixes?
Deploy in monitor-only mode first. Enable auto-remediation per playbook as confidence grows. The Decision Engine fuses ML confidence scores with admin-defined policy thresholds—only high-confidence, pre-approved actions execute automatically. Every action is logged with full rollback.
How does it integrate with ServiceNow?
Only when escalation is needed, the ReXGuardian AI Agent posts human-readable diagnostics into the ticket and attaches evidence. No standing integration required—escalation is event-driven and policy-controlled.
What NPU/GPU hardware is supported?
All DirectX 12-compatible silicon: NVIDIA, Intel, AMD, and Qualcomm NPUs/GPUs. On Windows 11 CoPilot+ PCs, inference automatically offloads to the dedicated NPU—no rebuilds, no configuration. Runs great on CPU-only endpoints today.
Deployment & footprint?
Lightweight agent built on .NET 8 and WinUI 3. Intune/SCCM ready (silent install, policy controls). No kernel hooks; security-first architecture. Resource-constrained watchdog timers prevent excessive CPU/memory use.
How are ML models and remediation packs updated?
Models and .rxdef packs are cryptographically signed and delivered through secure channels (Intune/SCCM or direct). The agent validates hashes before loading. Federated learning enables model improvement without uploading raw data—only encrypted weight diffs leave the device, if enabled by policy.