
Every on-device ML system faces the same fundamental tension. The models get smarter with more data. But the data lives on thousands of endpoints scattered across home offices, corporate campuses, and hotel Wi-Fi networks — and for very good reasons, you cannot centralize it.
At ReXLytics, when we built the on-device ML pipeline for ReXGuardianCA, we started with models trained on lab data and synthetic failure scenarios. They worked. The Siamese network caught configuration drift. The LightGBM classifier identified root causes. The TCN autoencoder flagged anomalous connection patterns. But they worked the way a textbook works — correctly, within the boundaries of what we had anticipated.
Production is not a textbook. Within weeks of pilot deployment, we were seeing failure patterns we had never engineered in a lab. A Windows Update pushed a new Intel NIC driver that silently broke IPsec offload on a specific chipset revision — connectivity worked fine for web traffic, but remote access tunnels dropped under sustained throughput. The failure only appeared on devices with that exact driver version and chipset combination, and only under load. Our lab models had never seen it because we had never tested that hardware permutation. But 300 endpoints in the fleet had, and 300 endpoints had learned — independently, without coordination — that this specific driver-chipset pair correlated with tunnel failures. The models needed to learn from that real-world signal. The data could not leave the device.
This is the problem federated learning was designed to solve.
Why Raw Telemetry Cannot Leave the Device
Before diving into the architecture, it is worth being explicit about why centralization is off the table. This is not an abstract privacy preference — it is an engineering constraint driven by multiple hard requirements.
Remote access telemetry contains sensitive operational data: connection logs that reveal which users are active at what times, server addresses that expose internal network topology, certificate metadata that identifies authentication infrastructure, and error logs that can contain credential fragments or internal hostnames. In regulated industries — finance, healthcare, government — this telemetry falls squarely under data protection frameworks like GDPR, CCPA, and sector-specific regulations like HIPAA.
Beyond regulatory compliance, there is a practical security argument. Centralizing raw connection telemetry from thousands of endpoints creates a high-value target. A breach of that aggregation point would expose the connectivity infrastructure topology for an entire organization. The attack surface of a centralized telemetry lake is significantly larger than the attack surface of telemetry that never leaves the endpoint.
And then there is the ironic operational constraint: the remote access client is the component most likely to be down when you need it. If your ML models depend on cloud connectivity to improve, you have introduced a circular dependency — the system that diagnoses connectivity failures requires connectivity to learn from those failures.
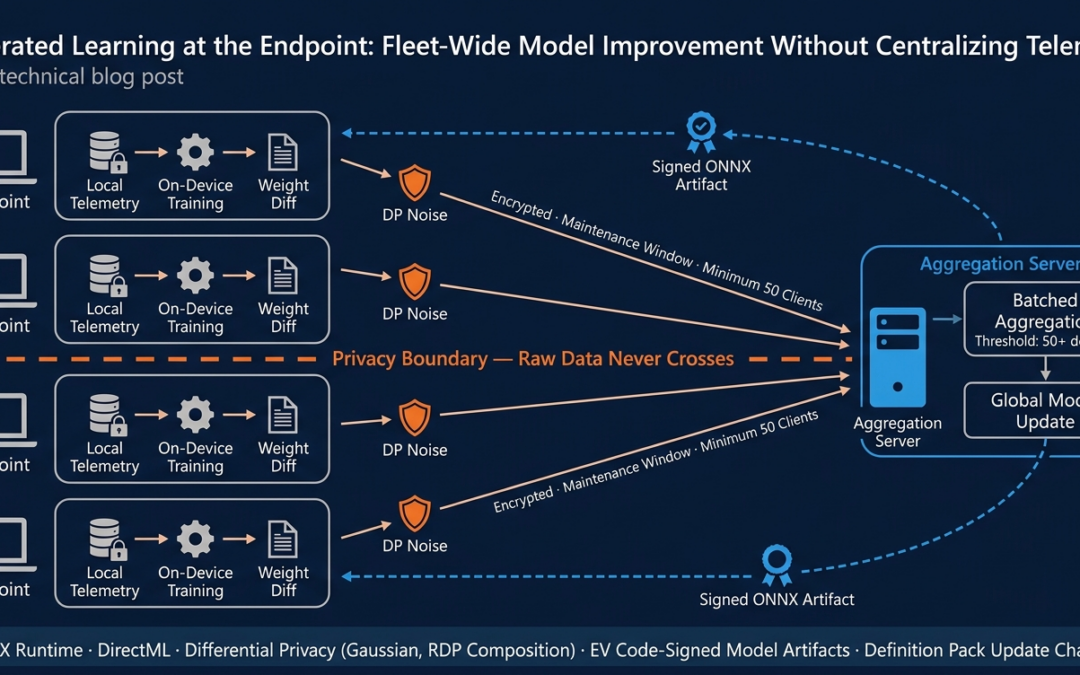
Our design principle is straightforward: raw telemetry never leaves the device. Only learned parameters — mathematical representations that are far more difficult to associate with the original data, and further protected by differential privacy noise — are transmitted during model improvement cycles.
The Federated Learning Loop
The architecture follows a standard federated learning pattern, adapted for the specific constraints of enterprise endpoint deployment.
Local Training Rounds. Each endpoint accumulates telemetry from its own remote access sessions — connection outcomes, configuration snapshots, performance metrics, error events. When sufficient new data has accumulated (we use a threshold of approximately 100 sessions, though this is configurable per deployment), the ReXGuardian AI Agent triggers a local training round. The on-device training pipeline — built into the agent and running against the ONNX Runtime execution environment — fine-tunes the existing model against this new local data. The key output is not a new model — it is a model weight diff, the delta between the pre-training weights and the post-training weights. This diff represents what this specific endpoint learned from its local experience.
Encrypted Gradient Transmission. The weight diff is serialized using a compact binary format, encrypted using the organization's public key, and queued for transmission. Transmission occurs during scheduled maintenance windows — not continuously, not on every training round, and never when the device is on battery or metered connectivity. This is a deliberate engineering choice. Federated learning does not require real-time gradient submission. The model improvement cycle operates on a timescale of days to weeks, not minutes.
Batched Aggregation. The aggregation server receives encrypted weight diffs from participating endpoints. The critical property of the batched aggregation protocol is that the server only computes an update after collecting contributions from many clients. It never processes any individual client's contribution in isolation. In practice, we implement this using a minimum participation threshold: the server waits until a minimum number of client updates (typically 50 or more devices) have been received before computing the aggregate. Below this threshold, the batch is discarded. This ensures that no single endpoint's learning is individually visible in the aggregate, even to the server operator.
Global Model Distribution. The aggregated weight update is applied to the global model. The updated model is then packaged as a signed ONNX artifact, distributed through the same definition pack update channel that delivers remediation logic, and deployed to endpoints during their next scheduled update cycle. Clients verify the model signature before loading it — the same cryptographic verification chain used for all definition pack content.
On-Device Training with ONNX Runtime
The on-device training pipeline we built for ReXGuardianCA leverages ONNX Runtime as the execution environment, making it practical to run training workloads on Windows endpoints without requiring a separate training framework installation.
The training workflow operates on ONNX model artifacts that have been specifically prepared for on-device training at authoring time. The training-ready model includes the forward graph (used for inference), the backward graph (used for computing gradients), and the optimizer state. At inference time, only the forward graph is loaded, keeping the runtime footprint unchanged. Training mode activates the full graph.
A local training round on a typical endpoint — running against 100-200 session records, with the model families we deploy — completes in under 30 seconds on CPU and under 10 seconds when DirectML acceleration is available through the NPU or integrated GPU. Memory overhead during training is approximately 2x the inference footprint of the model being trained, which for our lightweight models means we stay well under 200MB.
The output of a local training round is a checkpoint diff — a compact serialized representation of the delta between pre-training and post-training weight parameters. For our Siamese network (approximately 2MB model), a typical diff is 50-200KB. These are small enough to transmit over metered connections without concern, though we still defer transmission to maintenance windows as a matter of policy.
Not all on-device models participate in the federated loop. The LightGBM root-cause classifier is a gradient-boosted tree ensemble — its discrete tree structure does not lend itself to the continuous weight averaging that federated learning requires. Instead, we train LightGBM centrally and distribute updated models through the definition pack update channel, the same approach we use for the Phi Silica language model. The TCN autoencoder, which learns per-endpoint baseline patterns, is inherently personalized — aggregating its weights across endpoints would destroy the per-device adaptation that makes it useful. The federated learning loop operates on the Siamese drift detector, where cross-fleet learning produces clear accuracy improvements because configuration drift manifests differently across the diversity of endpoint environments.
Differential Privacy: Masking Individual Contributions
Batched aggregation ensures that no individual gradient update is processed in isolation. Differential privacy adds a second layer: ensuring that the aggregate itself does not leak information about any single endpoint's data.
The mechanism is straightforward in concept. Before transmitting its weight diff, each client adds calibrated random noise drawn from a Gaussian distribution. The noise is parameterized by the privacy budget (epsilon) — a smaller epsilon means more noise and stronger privacy guarantees, at the cost of noisier gradients that require more aggregation rounds to converge.
The implementation has several engineering considerations that matter in practice.
Clipping before noise injection. Each client's gradient update is clipped to a maximum L2 norm before noise is added. This prevents any single outlier endpoint — one that encountered an unusual failure pattern, for example — from disproportionately influencing the aggregate. The clipping bound is set based on empirical gradient magnitude distributions from our pilot deployments. Clipping too aggressively slows convergence. Clipping too loosely weakens the privacy guarantee.
Per-round privacy accounting. Each federated round consumes a portion of the total privacy budget. We track cumulative privacy spend using Rényi Differential Privacy (RDP) composition, which provides tighter accounting than naive sequential composition. This gives the operations team a clear dashboard: how much of the privacy budget has been consumed, how many more rounds can run before the budget is exhausted, and what the effective privacy guarantee is at any point in time.
Noise calibration to fleet size. The privacy-utility tradeoff improves naturally with more participating endpoints — each individual's contribution is diluted by the larger crowd, and the signal-to-noise ratio of the aggregate improves with scale. With 50 devices contributing to an aggregation round, each device's noise has a proportionally larger impact on the aggregate. With 500 devices, the same per-device noise is overwhelmed by the signal from the larger pool. This means the system automatically gets both more private and more accurate as the fleet grows.
The practical effect is that an adversary who gains access to the aggregated model update — even across multiple rounds — cannot determine whether any specific endpoint contributed to the training, what data that endpoint observed, or what failure patterns it encountered. The mathematical guarantee holds even against an adversary with access to the aggregation server itself.
The Honest Engineering Tradeoff: When Not to Use Federated Learning
Federated learning is not always the right answer. We deliberately chose not to federate all of our model update workflows, and the reasoning is worth discussing because I think the industry tends to reach for federated learning as a default when simpler approaches are often more appropriate.
When we use federated learning. The federated loop is most valuable when two conditions hold simultaneously: the model benefits meaningfully from real-world endpoint data that cannot be synthesized, and the data distribution across endpoints is heterogeneous enough that no single centralized dataset can capture it. Our Siamese drift detector meets both criteria. Configuration drift manifests differently across organizations, network environments, and remote access client stacks. A model trained only on lab data cannot anticipate the combinatorial explosion of real-world configuration states. Federated learning captures patterns from actual production environments without exposing the configurations themselves.
When we use periodic model pushes instead. For models where the training data can be adequately constructed from public or synthetic sources — or where the model architecture does not benefit from endpoint-specific adaptation — a simpler periodic update workflow is more appropriate. The Phi Silica language model, for example, is fine-tuned centrally against IT knowledge base articles, vendor documentation, and labeled failure-resolution pairs. This data is not endpoint-specific. There is no privacy benefit to federating it. We train centrally, validate against a held-out test set, sign the artifact, and push it through the standard definition pack update channel. This is simpler to operate, simpler to debug, and simpler to roll back if a model update causes issues.
The cost-benefit calculation. Federated learning introduces real operational complexity: maintaining the aggregation infrastructure, monitoring convergence, tracking privacy budgets, handling stragglers (devices that train but never transmit their diff), and debugging model quality issues when you cannot inspect the training data. For a fleet of 500 devices, the improvement in model accuracy from federated learning over periodic centralized pushes is measurable but modest — perhaps a 5-8% improvement in drift detection F1 score. At 5,000 devices, the improvement is substantial — 15-20% — because the diversity of endpoint environments provides training signal that no centralized dataset can replicate. The crossover point where federated learning clearly justifies its complexity varies by model and deployment, but in our experience it is somewhere around 1,000 endpoints.
Convergence and Non-IID Data
Enterprise endpoint fleets present a challenging data distribution for federated learning. The data is non-IID (not independently and identically distributed) in multiple dimensions: some endpoints are on corporate networks with managed infrastructure, others are on residential ISPs with consumer-grade equipment, and others are on hotel or airport Wi-Fi with unpredictable behavior. The failure modes, connection patterns, and configuration drift trajectories are fundamentally different across these environments.
Standard Federated Averaging (FedAvg) assumes that local data distributions are roughly similar. When they are not, the algorithm can oscillate — each local training round pulls the model toward a different region of the parameter space, and the global average ends up in a region that serves no endpoint well.
We address this through several mechanisms. First, the local training round uses a small learning rate and a limited number of local epochs (typically 3-5). This constrains how far any single endpoint can pull the model from the current global state. Second, we use momentum-corrected aggregation, where the server maintains a momentum buffer that dampens oscillation across rounds. Third, endpoints self-report a coarse environment category (corporate network, home network, public network) that is used to stratify the aggregation — updates from similar environments are weighted more heavily when computing the global update.
The result is that the global model converges to a state that performs well across the full diversity of endpoint environments, while individual endpoints can further personalize through local adaptation layers that are not part of the federated loop.
Security Considerations for the Aggregation Channel
The gradient transmission channel is a potential attack vector that requires specific defenses.
Byzantine fault tolerance. A compromised endpoint could submit malicious gradient updates designed to degrade the global model — for example, injecting updates that cause the drift detector to ignore specific configuration changes. We mitigate this through robust aggregation: rather than computing a simple mean of client updates, the server uses a coordinate-wise trimmed mean that discards statistical outliers before aggregation. This is computationally inexpensive and provides resilience against a small fraction of compromised clients.
Model update authentication. Every model artifact distributed to endpoints is signed using the same EV code-signing certificate used for the application binary and definition packs. Clients verify the signature before loading any model update. This prevents a man-in-the-middle attack on the model distribution channel.
Transmission confidentiality. Gradient diffs are encrypted in transit using the organization's infrastructure key pair. The aggregation server holds the private key. Endpoints encrypt with the public key, which is embedded in the client at deployment time and can be rotated through the definition pack update channel.
The Bigger Picture: Distributed Intelligence Without Distributed Data
The federated learning architecture addresses a specific engineering problem — improving on-device models without centralizing telemetry. But it connects to a broader pattern that I think is important for the industry.
Vijoy Pandey's work on the Internet of Cognition at Cisco's Outshift articulates a compelling vision: the next frontier for AI is not just scaling individual models up, but scaling intelligence out — enabling distributed agents to share learned knowledge without sharing raw data. His framing of "semantic isolation" as the core constraint on multi-agent systems resonates with what we see in endpoint fleets. Each ReXGuardian AI Agent on each endpoint is, in effect, an isolated intelligence. It observes patterns that no other agent sees. It learns from failures that no other agent experiences. Without a mechanism to share those learnings, the fleet operates as thousands of independent agents rather than a collective intelligence.
Federated learning is one concrete instantiation of that pattern — arguably the most mature one available today for production deployment. The gradient aggregation protocol is a narrow channel through which agents share compressed, privacy-preserving representations of what they have learned. It is not the rich semantic coordination that Pandey envisions for the Internet of Cognition, but it is a practical step in that direction: distributed intelligence, achieved without distributed data.
What We Learned
Building and operating the federated learning pipeline in production taught us several lessons that are not obvious from the research literature.
Start with centralized pushes and add federation later. Our initial deployment shipped with centrally trained models and a simple periodic update workflow. We instrumented the endpoints to measure where the centralized models underperformed, identified the model families that would benefit most from real-world data, and then added the federated loop for those specific models. This incremental approach let us validate the federated infrastructure against a known baseline rather than debugging model quality and aggregation infrastructure simultaneously.
The aggregation threshold matters more than the privacy budget. In early testing, we spent significant engineering time tuning epsilon for the differential privacy noise. What actually had the largest impact on both privacy and model quality was the minimum aggregation threshold — the number of client updates required before the server computes an aggregate. A higher threshold provides stronger privacy (more contributions masking each individual) and better convergence (more diverse data in each round). We found that increasing the threshold from 20 to 50 devices improved both privacy and accuracy, at the cost of slower round frequency. For most enterprise deployments, this is the right tradeoff.
Maintenance window scheduling is a solved problem — use it. We initially designed a complex adaptive scheduling system for gradient transmission. We replaced it with a simple integration into the organization's existing maintenance window policy. IT teams already define when background updates can run. Aligning gradient transmission with that window eliminates the need for custom scheduling logic, avoids user-visible network activity during work hours, and ensures that the aggregation server receives batches of updates at predictable intervals rather than a trickle.
Monitor convergence, not just accuracy. A federated model can achieve reasonable accuracy while failing to converge — oscillating between updates without settling into a stable state. We added convergence monitoring that tracks the L2 norm of the aggregated update across rounds. A declining norm indicates convergence. A flat or increasing norm indicates that the data distribution is too heterogeneous for the current aggregation strategy and the stratification parameters need adjustment.
The result is a model improvement system that learns from the collective experience of the fleet — every endpoint contributing to the intelligence of every other endpoint — without any single device's raw telemetry ever leaving the hardware it was generated on.
Emmett O’Brien leads the engineering organization behind ReXLytics’ Hybrid Work ERP platform and the Edge-AI-powered ReXGuardian suite for enterprise connectivity and cybersecurity. Learn more at ReXLytics.com or connect with Emmett O’Brien on LinkedIn.
Ready to eliminate remote-access downtime?Schedule a 30-minute demo to see ReXGuardianCA in action.Contact Sales →